Доклад: обучение с подкреплением
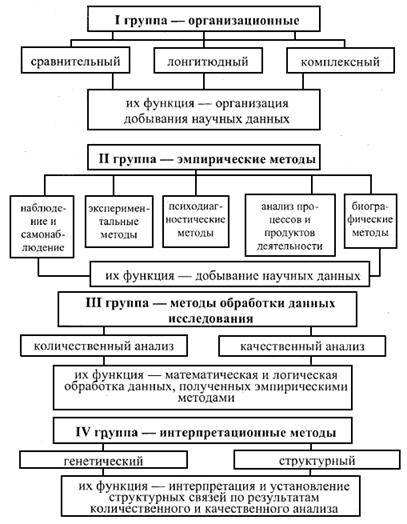
Алгоритмы
Теперь, когда была определена функция выигрыша, нужно определить алгоритм, который будет использоваться для нахождения стратегии, обеспечивающей наилучший результат.
Наивный подход к решению этой задачи подразумевает следующие шаги:
- опробовать все возможные стратегии;
- выбрать стратегию с наибольшим ожидаемым выигрышем.
Первая проблема такого подхода заключается в том, что количество доступных стратегий может быть очень велико или же бесконечно.
Вторая проблема возникает, если выигрыши стохастические — чтобы точно оценить выигрыш от каждой стратегии потребуется многократно применить каждую из них.
Этих проблем можно избежать, если допустить некоторую структуризацию и, возможно, позволить результатам, полученным от пробы одной стратегии, влиять на оценку для другой.
Двумя основными подходами для реализации этих идей являются оценка функций полезности и прямая оптимизация стратегий.
Подход с использованием функции полезности использует множество оценок ожидаемого выигрыша только для одной стратегии (либо текущей, либо оптимальной).
При этом пытаются оценить либо ожидаемый выигрыш, начиная с состояния s, при дальнейшем следовании стратегии ,
-
- ,
либо ожидаемый выигрыш, при принятии решения a в состоянии s и дальнейшем соблюдении ,
-
- .
Если для выбора оптимальной стратегии используется функция полезности Q, то оптимальные действия всегда можно выбрать как действия, максимизирующие полезность.
Если же мы пользуемся функцией V, необходимо либо иметь модель окружения в виде вероятностей P(s’|s,a), что позволяет построить функцию полезности вида
-
- ,
либо применить т.н. метод исполнитель-критик, в котором модель делится на две части: критик, оценивающий полезность состояния V, и исполнитель, выбирающий подходящее действие в каждом состоянии.
Имея фиксированную стратегию , оценить при можно просто усреднив непосредственные выигрыши.
Наиболее очевидный способ оценки при — усреднить суммарный выигрыш после каждого состояния.
Однако для этого требуется, чтобы МППР достиг терминального состояния (завершился).
Поэтому построение искомой оценки при неочевидно. Однако, можно заметить, что R образуют рекурсивное уравнение Беллмана:
-
- .
Указанные методы не только сходятся к корректной оценке для фиксированной стратегии, но и могут быть использованы для нахождения оптимальной стратегии
Для этого в большинстве случаев принимают стратегию с максимальной оценкой, принимая иногда случайные шаги для исследования пространства.
При выполнении некоторых дополнительных условий существуют доказательства сходимости упомянутых методов к оптимальной стратегии.
Однако, эти доказательства гарантируют только асимптотическую сходимость, в то время как поведение алгоритмов обучения с подкреплением в задачах с малыми выборками мало изучено, не считая некоторых очень ограниченных случаев.
Альтернативный метод поиска оптимальной стратегии — искать непосредственно в пространстве стратегий.
Таки методы определяют стратегию как параметрическую функцию с параметром .
Для настройки параметров применяются градиентные методы.
Однако, применение градиентных методов осложняется тем, что отсутствует информация о градиенте.
Более того, градиент тоже приходится оценивать через зашумлённые результаты выигрышей.
Так как это существенно увеличивает вычислительные затраты, может быть выгоднее использовать более мощные градиентные методы, такие как метод скорейшего спуска.
Алгоритмы, работающие напрямую с пространством стратегий привлекли значительное внимание в последние 5 лет и в данный момент достигли достаточно зрелой стадии, но до сих пор остаются активным полем для исследований.
Существуют и другие подходы, такие как метод отжига, применяемые для исследования пространства стратегий.
Система подкрепления и её виды
Розенблатт пытался классифицировать различные алгоритмы обучения, называя их системами подкрепления. Он даёт следующее определение:
Кроме классического метода обучения перцептрона — метода коррекции ошибки, который можно отнести к обучению с учителем, Розенблатт также ввёл понятие об обучении без учителя, предложив несколько способов обучения:
- Альфа-системой подкрепления называется система подкрепления, при которой веса всех активных связей cij{\displaystyle c_{ij}}, которые ведут к элементу uj{\displaystyle u_{j}}, изменяются на одинаковую величину r, а веса неактивных связей за это время не изменяются.
- Гамма-системой подкрепления называется такое правило изменения весовых коэффициентов некоторого элемента, при котором веса всех активных связей сначала изменяются на равную величину, а затем из их всех весов связей вычитается другая величина, равная полному изменению весов всех активных связей, делённому на число всех связей. Эта система обладает свойством консервативности относительно весов, так как у неё полная сумма весов всех связей не может ни возрастать, ни убывать.
Шаг 2: Решение
Авторы представили отличное интерактивное объяснение своей методологии, поэтому не будем вдаваться в подробности, а лучше сосредоточимся на кратком обзоре того, как части решения взаимодействуют друг с другом, и проведем аналогию с реальным вождением, чтобы объяснить интуитивный смысл.
Решение состоит из трех отдельных частей, которые обучаются отдельно:
Вариационный автоэнкодер (VAE)
В процессе вождения машины вы не будете активно анализировать каждый «пиксель» того, что видите. Вместо этого ваш мозг превращает визуальную информацию в меньшее количество «скрытых» признаков, таких как прямолинейность дороги, предстоящие изгибы и позицию относительно дороги, чтобы подумать и сообщить о следующем действии.









Это именно то, чему обучается VAE — сжимать входное изображение 64x64x3 (RGB) в 32-мерный скрытый вектор z, удовлетворяющий нормальному распределению.
Такое представление визуального окружения полезно, т.к. гораздо меньше по размеру, и агент может обучаться эффективнее.
Рекуррентная нейронная сеть с сетью смеси распределений на выходе (Recurrent Neural Network with Mixture Density Network output, MDN-RNN)
Если в принятии решений вы обходитесь без компонента MDN-RNN, ваше вождение может выглядеть примерно так. Когда вы едете на машине, каждое последующее наблюдение не является для вас полной неожиданностью. Вы знаете, что если в данный момент окружение предполагает поворот налево на дороге, и вы поворачиваете колеса влево, вы ожидаете, что следующий кадр покажет, что вы все еще на одной линии с дорогой.
Подобное мышление наперед — суть работы RNN, сети долгой краткосрочной памяти (LSTM) с 256 скрытыми значениями. Вектор скрытых состояний обозначим за h.
Подобно VAE, RNN пытается зафиксировать внутреннее «понимание» текущего состояния автомобиля в своем окружении, но на этот раз с целью предсказать, как будет выглядеть последующий z на основе предыдущего z и совершённого действия.
Выходной слой MDN просто учитывает тот факт, что следующий z может быть фактически выведен из любого из нескольких нормальных распределений.
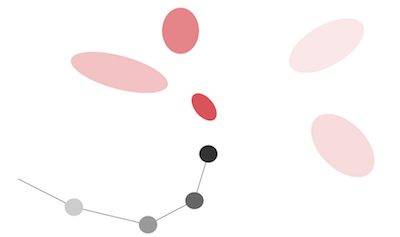 MDN для генерации почерка
MDN для генерации почерка
Тот же автор применил данный метод в этой статье для задачи генерации почерка, чтобы описать тот факт, что следующая точка пера может оказаться в любой из красных отдельных областей.
Аналогично, в статье «Модели мира» следующее наблюдаемое скрытое состояние может быть составлено из любого из пяти гауссовских распределений.
Контроллер
До этого момента мы ничего не говорили о выборе действия. Эта ответственность лежит на Контроллере.
Контроллер — это обычная полносвязная нейронная сеть, где вход представляет собой конкатенацию z (текущее скрытое состояние от VAE, длина 32) и h (скрытое состояние RNN, длина 256). 3 выходных нейрона соответствуют трем действиям, их значения масштабируются для попадания в соответствующие диапазоны.
Диалог
Чтобы понять разные роли трех компонентов и то, как они работают вместе, можно представить себе своеобразный диалог между ними:
VAE: (смотрит последнее наблюдение размера 64 * 64 * 3) “Это выглядит как прямая дорога, с легким левым поворотом, приближающимся к машине, движущейся вдоль дороги”.
RNN: “Из того, что мне описал VAE (вектор z) и того факта, что Контроллер решил ускориться на последнем шаге, я обновлю свое скрытое состояние (h), чтобы предсказание следующего наблюдения все еще была прямая дорога, но с чуть более сильным левым поворотом”.
Контроллер: “На основании описания из VAE (z) и текущего скрытого состояния из RNN (h) моя нейронная сеть выводит следующее действие как ”.
Затем это действие передается в окружение, которая возвращает новое наблюдение, и цикл повторяется снова.
Теперь мы рассмотрим, как настроить среду, которая позволяет вам обучать собственную версию агента для автогонок.
Пора писать код!
Исследование
Темы исследований включают
- адаптивные методы, которые работают с меньшим количеством (или нет) параметров, при большом числе условия
- решение проблемы геологоразведки в больших МДП
- крупномасштабные эмпирические оценки
- обучения и действуя на основании неполной информации (например, с помощью предиктивного государственного представительства )
- модульное и иерархическое обучение с подкреплением
- совершенствование существующих значений-функции и политика методы поиска
- алгоритмы, которые хорошо работают с большими (или непрерывным) пространствах действиями
- обучение передачи
- на протяжении всей жизни
- эффективной выборки на основе планирования (например, на основе Монте — Карло поиска по дереву ).
- Обнаружение ошибки в программных проектах
Многоагентное или распределенное обучение армирования является предметом интереса. Приложения расширяются.



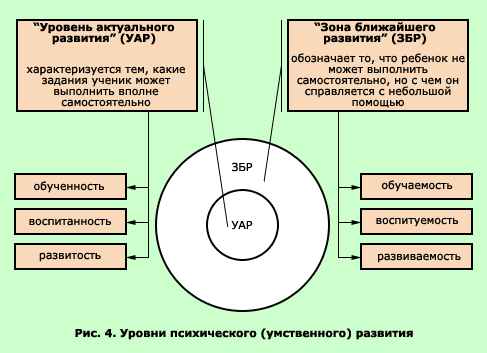




Актер-Критик Армирование обучение
Алгоритмы обучения с подкреплением , такие как обучение TD находятся под следствием в качестве модели для допамина -На обучения в головном мозге. В этой модели, дофаминергические проекции от черной субстанции к базальных ганглиев функции в качестве ошибки предсказания. Обучение Армирования используется в качестве части модели для изучения навыков человека, особенно в отношении взаимодействия между неявным и явным обучением в приобретении навыков (первая публикация по данной заявке была в 1995-1996 год).
Шаг 9: Визуализация работы агента
На момент написания статьи мне удалось подготовить агента для достижения среднего балла ~833,13 после 200 поколений обучения. Запуски проводились в Google Cloud под Ubuntu 16.04, 18 vCPU, 67,5 ГБ оперативной памяти с шагами и параметрами, приведенными в этом уроке.
Авторам статьи удалось достичь среднего балла ~906, после 2000 поколений обучения, который считается самым высоким показателем в этой виртуальной среде на сегодняшний день. Были использованы несколько более высокие настройки (например, 10 000 эпизодов учебных данных, 64 размер популяции, 64-ядерная машина, 16 эпизодов за испытание и т. д.).
Чтобы визуализировать текущее состояние вашего контроллера, запустите:
python model.py car_racing --filename ./controller/car_racing.cma.4.32.best.json --render_mode --record_video
: путь к json-файлу весов, который вы хотите подключить к контроллеру
: отображение среды на экране
: выводит файлы mp4 в папку , показывая каждый эпизод
: выполняет 100 эпизодов в тестовом режиме контроллера и выводит средний балл.
Пример работы

теория
И асимптотическое и конечно-образец поведение большинства алгоритмов хорошо понимают. Алгоритмы с доказуемо хорошей онлайн производительности (решение проблемы геологоразведки) известны.
Эффективное освоение крупного МДПА в значительной степени неисследованное (для случая проблем бандитских за исключением). Хотя конечное время оценка производительности оказалась для многих алгоритмов, эти оценки, как ожидается, будет достаточно рыхлыми и, таким образом, больше работы, чтобы лучше понять относительные преимущества и недостатки.
Для инкрементальных алгоритмов, асимптотические вопросы сходимости были решены. Височно-разностные алгоритмы на основе сходятся при более широком наборе условий, чем это было возможно ранее (например, при использовании с произвольным гладкой функцией, приближением).
Какие аргументы приводят противники положительного подкрепления и почему эти аргументы несостоятельны?
У положительного подкрепления есть и сторонники, и противники. Основные аргументы против использования исключительно положительного подкрепления:
- «Положительное подкрепление – это подкуп собаки».
- «Положительное подкрепление не формирует стабильный навык».
- «Положительное подкрепление – это вседозволенность».
Однако ни один из этих аргументов не является хоть сколько-нибудь состоятельным.
Если говорить о подкупе, то противники положительного подкрепления подменяют понятия. Подкуп – это когда вы показываете собаке лакомство или игрушку и подзываете. Да, во время обучения, чтобы собака поняла, что от нее требуется, мы, безусловно, учим ее подбегать на вкусный кусочек или игрушку – но только на этапе объяснения. А если вы позвали собаку, не подманивая ее, похвалили в момент, когда она отвернулась от других собак или от интересных запахов в траве и побежала к вам, а когда подбежала, играете с ней или угощаете – это не подкуп, а оплата.









Так что о подкупе речь точно не идет.
Те, кто говорят «Мы пробовали положительное подкрепление, но оно не формирует стабильный навык», вероятно, допускали ошибки в дрессировке собак. И одна из таких ошибок – резкое усложнение задачи.
Прежде чем переходить к следующему этапу, нужно убедиться в том, что собака понимает задачу. Если задачу усложнять постепенно, не пропускать важные этапы обучения и правильно выбирать способ мотивации, собака будет показывать отличный результат при обучении методом положительного подкрепления, причем стабильно.
К тому же, в положительном подкреплении используется метод «вариативного подкрепления», когда награда выдается не каждый раз, и собака не знает, получит ли она бонус за выполнение команды. Вариативное подкрепление более действенно, чем выдача приза после каждой команды. Разумеется, этот способ используется, когда навык уже сформирован, и собака точно понимает, чего вы от нее хотите. Это тоже обеспечивает стабильность выполнения команд.
Еще один аргумент противников положительного подкрепления – это «вседозволенность». «Собака сядет на шею!» — возмущаются они. Но вседозволенность – это когда владелец не вмешивается в поведение собаки, и она делает что хочет (хочет – ловит кошек, хочет – грызет обувь и т.п.) Однако, используя положительное подкрепление, мы обучаем собаку, объясняем правила совместного проживания и помогаем приспособиться к разумным ограничениям, подсказывая, каким образом она может удовлетворить свои потребности – просто делаем это гуманно. То есть с вседозволенностью положительное подкрепление тоже не имеет ничего общего.
Шаг 7: Обучение рекуррентной нейросети
Для обучения RNN требуется только и . Убедитесь, что вы успешно выполнили шаг 6, и файлы находятся в папке .
В командной строке выполните:
python 04_train_rnn.py --start_batch 0 --max_batch 9 --new_model
Это запустит процессы обучения новых RNN для каждого пакета данных от 0 до 9.
Веса модели будут сохранены в . Флаг сообщает скрипту, что модель нужно подготавливать с нуля.
Аналогично VAE, если в этой папке существуют, а флаг не указан, скрипт загрузит веса из этого файла и продолжит тренировку существующей модели. Аналогично это позволяет итеративно обучать RNN партиями.
Спецификация архитектуры RNN находится в файле .
Шаг 3. Настройка среды
Если у вас компьютер с высокой производительностью, вы можете запускать решение локально, но я бы рекомендовал использовать Google Cloud Compute для доступа к мощным машинам.
Описанное ниже было проверено на Linux (Ubuntu 16.04); если вы используете Mac или Windows, измените соответствующие команды установки пакетов.
Склонируйте репозиторий
В командной строке, перейдите в папку, в которую вы хотите сохранить репозиторий, и введите следующее:
git clone https://github.com/AppliedDataSciencePartners/WorldModels.git
Репозиторий адаптирован из весьма полезной библиотеки estool, разработанной Дэвидом Ха, первым автором статьи «Модели мира».
Для обучения нейронной сети данная реализация использует Keras над Tensorflow, хотя в оригинальной статье авторы использовали чистый Tensorflow.
Настройте виртуальную среду
Создайте себе виртуальную среду (virtual environment) для Python 3 (я использую и ):
sudo apt-get install python-pip sudo pip install virtualenv sudo pip install virtualenvwrapper export WORKON_HOME = ~/.virtualenvs source /usr/local/bin/virtualenvwrapper.sh mkvirtualenv --python=/usr/bin/python3 worldmodels
Установите пакеты
sudo apt-get install cmake swig python3-dev zlib1g-dev python-opengl mpich xvfb xserver-xephyr vnc4server
Установите requirements.txt
cd WorldModels pip install -r requirements.txt
Эта команда устанавливает больше, чем нужно для примера с гонками. Зато если вы захотите протестировать другие окружения от Open AI, для которых требуются дополнительные пакеты, у вас будет все необходимое.








Среда и агент
Агент воздействует на среду, а среда воздействует на агента. О такой системе говорят, что она имеет обратную связь. Такую систему нужно рассматривать как единое целое, и поэтому линия раздела между средой и агентом достаточно условна. Конечно, с анатомической или физической точек зрения между средой и агентом (организмом) существует вполне определённая граница, но если эту систему рассматривать с функциональной точки зрения, то разделение становится нечётким. Например, резец в руке скульптора можно считать либо частью сложного биофизического механизма, придающего форму куску мрамора, либо частью материала, которым пытается управлять нервная система.
Впервые такого рода обучение с обратной связью было предложено и изучено в 1961 году в работе Михаила Львовича Цетлина, известного советского математика.
М. Л. Цетлин тогда поместил конечный автомат определённой конструкции во внешнюю среду, которая с вероятностями, зависящими от совершаемого автоматом действия, наказывала или поощряла автомат. В соответствии с реакцией среды автомат самостоятельно изменял своё внутреннее состояние, что приводило к постепенному снижению числа наказаний, то есть обучению.
Для анализа поведения этого автомата был впервые использован аппарат цепей Маркова, разработанный А. А. Марковым, который позволил получить точные и доказательные результаты.
Этот материал был опубликован в одном из наиболее престижных и влиятельных научных советских изданий — «Доклады Академии наук СССР». М. Л. Цетлин называл эту проблему изучением поведения автомата в случайной среде.
Статья М. Л. Цетлина вызвала волну публикаций, в которых предлагались всевозможные усовершенствования конструкций конечных автоматов, интенсивно использовавшиеся в многочисленных приложениях.
М. Л. Цетлин ввёл в оборот новый термин — целесообразное поведение автомата в случайной среде. Его ученик, В. Л. Стефанюк, рассмотрел в 1963 году задачу о коллективном поведении, определив новый термин — «коллективное поведение автоматов» и детально исследовав поведение пары автоматов, введённых М. Л. Цетлиным в его первой публикации о целесообразном поведении автоматов.
В. Л. Стефанюком была изготовлена действующая обучающаяся модель на полупроводниковых элементах и вакуумных радиолампах, в которой было реализовано коллективное поведение двух таких автоматов. Эта модель была защищена в 1962 году в качестве выпускной работы на Физическом факультете Московского государственного университета.
В это же время (1963) М. Л. Цетлиным была сформулирована задача об играх автоматов, которая моделировала несколько важных проблем биологии и социологии. Несколько позже М. Л. Цетлин и С. Л. Гинзбург описали конструкцию так называемого ε-автомата, который часто используется в современных публикациях по обучению с подкреплением.
Многочисленные советские публикации о целесообразном поведения автоматов, доложенные на национальных и международных конференциях, через много лет навели авторов обучения с подкреплением на мысль о выделении этого типа обучения в отдельный класс.
Что касается коллективного поведения автоматов, то что-то подобное вылилось у зарубежных авторов в концепцию многоагентных систем, которая изучалась в терминах искусственного интеллекта и программирования. Однако математические методы анализа и доказательства в многоагентных системах практически не использовались, в отличие от работ М. Л. Цетлина и В. Л. Стефанюка по целесообразному поведению автомата, а также по коллективному поведению и играм нескольких автоматов.
Вступление
Типичное обрамление сценария подкрепления (RL): агент совершает действия в среде, которая интерпретируется в качестве вознаграждения и представительство государства, которые подаются обратно в агент.
Основное усиление моделируются как процесс принятия решений Маркова :
- набор окружающей среды и агентов состояний, S ;
- набор действий, A , агента;
- пa(s,s’)знак равнопр(sT+1знак равноs’|sTзнак равноs,aTзнак равноa){\ Displaystyle Р- {а} (S, S ‘) = Pr (S_ {Т + 1} = s’ | S_ {т} = с, а_ {т} = а)}вероятность перехода из состояния заявить под действием .s{\ Displaystyle s}s'{\ Displaystyle s’}a{\ Displaystyle а}
- рa(s,s’){\ Displaystyle R_ {а} (S, S’)}является немедленное вознаграждение после перехода от к с действием .s{\ Displaystyle s}s'{\ Displaystyle s’}a{\ Displaystyle а}
- правила, которые описывают то, что наблюдает агент
Правила часто стохастические . Наблюдение , как правило , включает в себя скалярное, немедленное вознаграждение , связанное с последним переходом. Во многих работах предполагается , что агент для наблюдения текущего состояния окружающей среды ( полная наблюдаемость ). Если нет, то агент имеет частичную наблюдаемость . Иногда набор действий , доступных агенту ограничен (нулевой баланс не может быть уменьшен).
Обучающееся армирование агент взаимодействует со средой в дискретных временных шагах. В каждый момент времени т , агент получает наблюдение , которое , как правило , включает в себя вознаграждение . Затем он выбирает действие из множества доступных действий, который впоследствии отправляется на окружающую среду. Окружающая среда перемещается в новое состояние и награды , связанные с переходом определяются. Цель учебного армирования агента , чтобы собрать как можно больше вознаграждения , насколько это возможно. Агент может (возможно случайно) выбрать любое действие , в зависимости от истории.
оT{\ Displaystyle o_ {т}}рT{\ Displaystyle r_ {т}}aT{\ Displaystyle a_ {т}}sT+1{\ Displaystyle S_ {T + 1}}рT+1{\ Displaystyle R_ {T + 1}} (sT,aT,sT+1){\ Displaystyle (S_ {T}, а_ {T}, S_ {T + 1})}
Когда производительность агента сравнивают с агентом , который действует оптимально, разница в производительности приводит к понятию сожаления . Для того , чтобы действовать вблизи оптимально, агент должен рассуждать о долгосрочных последствиях своих действий (т.е. максимизировать доход в будущем), хотя непосредственная награда , связанная с этим может быть отрицательной.
Таким образом, обучение с подкреплением особенно хорошо подходят для задач , которые включают в себя долгосрочный против краткосрочного вознаграждения компромисса. Он был успешно применен к различным проблемам, в том числе управления роботом , планирования лифта, телекоммуникаций , нарды , шашки и идти ( AlphaGo ).









Два элемента делает армирование обучения мощным: использование образцов для оптимизации производительности и использования функции приближения для решения больших сред. Благодаря этим двум ключевым компонентам, обучение с подкреплением может быть использован в больших средах в следующих ситуациях:
- Модель среды известна, но аналитическое решение не доступен;
- Только имитационная модель окружающей среды дается (субъект моделирования на основе оптимизации );
- Единственный способ для сбора информации об окружающей среде, чтобы взаимодействовать с ним.
Первые два из этих проблем можно было бы рассматривать проблемы планирования (поскольку некоторая форма модели доступна), в то время как последний может считаться подлинной проблемой обучения. Тем не менее, обучение с подкреплением преобразует обе проблемы планирования для машинного обучения проблем.